Anomaly Detection in Network Intrusion Detection Systems Using Machine Learning and Dimensionality Reduction
Keywords:
Network Intrusion Detection, Machine Learning Algorithms, NSL-KDD Dataset, Dimensionality Reduction, Principal Component Analysis (PCA), CybersecurityAbstract
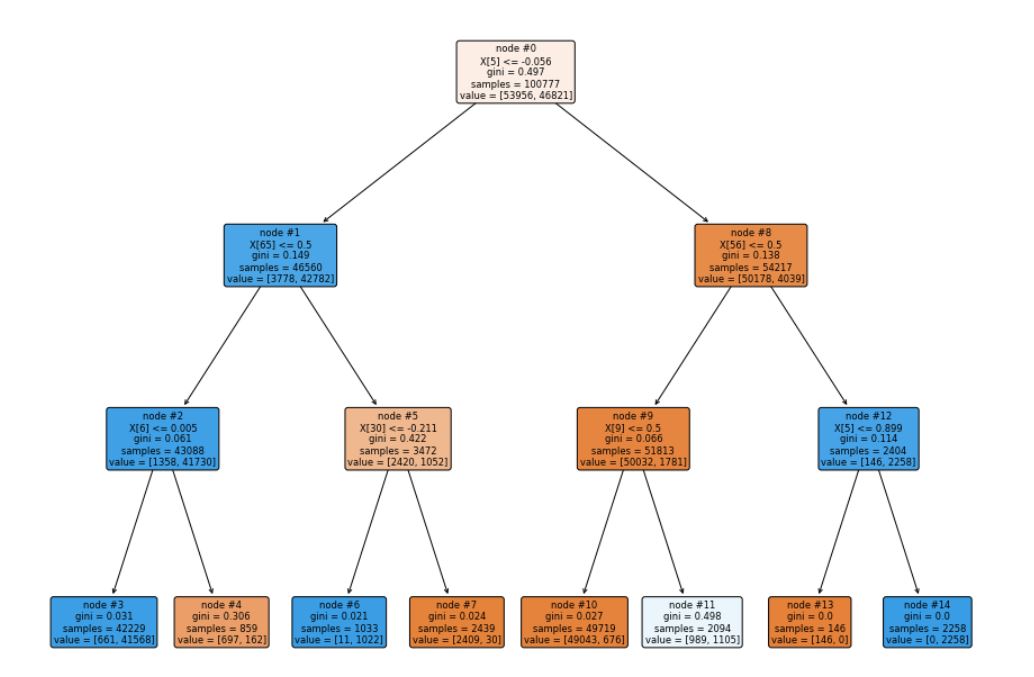
A fundamental aspect of cybersecurity is the detection of network intrusions, which pose a significant threat to the confidentiality and integrity of sensitive data. Network Intrusion Detection Systems (NIDS) are crucial tools for identifying and responding to unauthorized access or malicious activities within a network. This study investigates the efficacy of various machine learning algorithms for the classification of network traffic into normal and anomalous categories, employing the NSL-KDD dataset as a benchmark. We apply a rigorous preprocessing pipeline, including feature scaling and dimensionality reduction using Principal Component Analysis (PCA). The dataset contains 122 original features, which are reduced to 20 principal components while preserving meaningful information. To assess the performance of our models, we utilize seven different machine learning algorithms: Logistic Regression, K-Neighbors Classifier, Gaussian Naive Bayes (Gaussian NB), Linear Support Vector Classifier (Linear SVC), Decision Tree Classifier, Random Forest Classifier, and a variant of Random Forest with PCA. The following metrics are employed for evaluation: training and test accuracy, precision, and recall. Logistic Regression exhibits competitive results with a training accuracy of 86.97% and a test accuracy of 86.62%. K-Neighbor Classifier surpasses other models with training accuracy (98.05%) and test accuracy (97.94%). Gaussian NB, Linear SVC, Decision Tree Classifier, and Random Forest Classifier all exhibit good performance, consistently achieving high accuracy, precision, and recall scores. Incorporating PCA into the Random Forest Classifier provides a minimal reduction in performance, ensuring that dimensionality reduction does not compromise the model's effectiveness. The PCA Random Forest demonstrates a training accuracy of 98.99% and a test accuracy of 98.83%. Our findings suggest the suitability of these machine learning algorithms for intrusion detection tasks, with K-Neighbors Classifier standing out as the most robust performer in this study. Dimensionality reduction via PCA found streamlining computation without a significant sacrifice in model accuracy. This came at the expense of a slight reduction in recall, indicating a trade-off between precision and sensitivity to positive instances. The Random Forest analysis identified login attempts as the most crucial feature for network classification in intrusion detection, followed by the rate of contacting different destination hosts for the same service. Moreover, according to the findings of this study, Guest vs. non-guest logins, data volume transfer, service type, and service rate variations were also vital factors for accurate network traffic classification.