The Role of Apache Hadoop and Spark in Revolutionizing Financial Data Management and Analysis: A Comparative Study
Keywords:
Financial data analysis, Emerging technologies, Machine learning algorithms, Blockchain integration, Edge computing, Quantum computing, ScalabilityAbstract
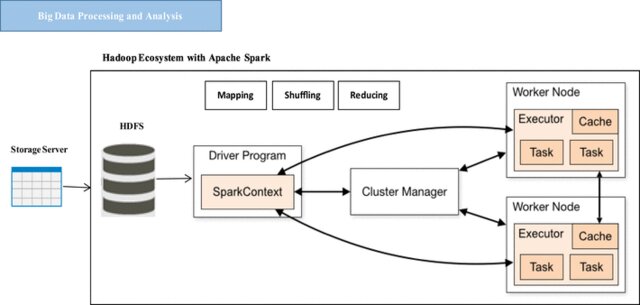
This research article delves into the transformative impact of Apache Hadoop and Apache Spark on the management and analysis of financial data, presenting an exhaustive comparative evaluation of the two technologies. Financial institutions, grappling with immense volumes of structured and unstructured data, are increasingly turning to big data solutions to derive actionable insights, manage risk, and optimize decision-making processes. This study undertakes a multi-faceted analysis, considering key parameters such as scalability, fault tolerance, data processing speed, and ecosystem diversity, to evaluate the suitability of Apache Hadoop and Spark for various financial data analytics tasks. Through a series of benchmark tests and real-world case studies, the research quantifies performance metrics and evaluates operational efficiencies. It also considers the cost implications, ease of integration, and adaptability of these technologies in a financial environment that is governed by stringent regulations and compliance requirements. Additionally, the study identifies specific use-cases where one technology may outperform the other, such as high-frequency trading analysis, fraud detection, and customer segmentation. By offering a thorough comparison grounded in empirical data, this research aims to serve as a comprehensive guide for financial professionals, data scientists, and organizations. It provides actionable insights that can inform the strategic implementation of big data technologies, thereby enabling more effective data management and analytics in the financial sector.
Downloads
Published
How to Cite
Issue
Section
License
CC Attribution-NonCommercial-ShareAlike 4.0

